ARM PROCESSOR
Introduction

ARM, previously Advanced RISC Machine, originally Acorn RISC Machine, is a family of reduced instruction set computing (RISC) architectures for computer processors, configured for various environments. Arm Holdings develops the architecture and licenses it to other companies, who design their own products that implement one of those architectures—including systems-on-chips (SoC) and systems-on-modules (SoM) that incorporate memory, interfaces, radios, etc. It also designs cores that implement this instruction set and licenses these designs to a number of companies that incorporate those core designs into their own products.
Processors that have a RISC architecture typically require fewer transistors than those with a complex instruction set computing (CISC) architecture (such as the x86 processors found in most personal computers), which improves cost, power consumption, and heat dissipation. These characteristics are desirable for light, portable, battery-powered devices—including smartphones, laptops and tablet computers, and other embedded systems.[3][4][5] For supercomputers, which consume large amounts of electricity, ARM could also be a power-efficient solution.[6]
Arm Holdings periodically releases updates to the architecture. Architecture versions ARMv3 to ARMv7 support 32-bit address space (pre-ARMv3 chips, made before Arm Holdings was formed, as used in the Acorn Archimedes, had 26-bit address space) and 32-bit arithmetic; most architectures have 32-bit fixed-length instructions. The Thumb version supports a variable-length instruction set that provides both 32- and 16-bit instructions for improved code density. Some older cores can also provide hardware execution of Java bytecodes; and newer ones have one instruction for JavaScript. Released in 2011, the ARMv8-A architecture added support for a 64-bit address space and 64-bit arithmetic with its new 32-bit fixed-length instruction set.DESCRIPTION

Processor have a RISC architecture typically require fewer transistors than those with a complex instruction set computing (CISC) architecture (such as the x86 processors found in most personal computers), which improves cost, power consumption, and heat dissipation. These characteristics are desirable for light, portable, battery-powered devices—including smartphones, laptops and tablet computers, and other embedded systems.For supercomputers, which consume large amounts of electricity, ARM could also be a power-efficient solution.
Arm Holdings periodically releases updates to the architecture. Architecture versions ARMv3 to ARMv7 support 32-bit address space (pre-ARMv3 chips, made before Arm Holdings was formed, as used in the Acorn Archimedes, had 26-bit address space) and 32-bit arithmetic; most architectures have 32-bit fixed-length instructions. The Thumb version supports a variable-length instruction set that provides both 32- and 16-bit instructions for improved code density. Some older cores can also provide hardware execution of Java bytecodes; and newer ones have one instruction for JavaScript. Released in 2011, the ARMv8-A architecture added support for a 64-bit address space and 64-bit arithmetic with its new 32-bit fixed-length instruction set.
With over 100 billion ARM processors produced as of 2017, ARM is the most widely used instruction set architecture and the instruction set architecture produced in the largest quantity.Currently, the widely used Cortex cores, older "classic" cores, and specialized SecurCore cores variants are available for each of these to include or exclude optional capabilities.
ARM processor features include:
- Load/store architecture.
- An orthogonal instruction set.
- Mostly single-cycle execution.
- Enhanced power-saving design.
- 64 and 32-bit execution states for scalable high performance.
- Hardware virtualization support.
The simplified design of ARM processors enables more efficient multi-core processing and easier coding for developers. While they don't have the same raw compute throughput as the products of x86 market leader Intel, ARM processors sometimes exceed the performance of Intel processors for applications that exist on both architectures.
The head-to-head competition between the vendors is increasing as ARM is finding its way into full size notebooks. Microsoft, for example, offers ARM-based versions of Surface computers. The cleaner code base of Windows RT versus x86 versions may be also partially responsible -- Windows RT is more streamlined because it doesn’t have to support a number of legacy hardwares.
ARM is also moving into the server market, a move that represents a large change in direction and a hedging of bets on performance-per-watt over raw compute power. AMD offers 8-core versions of ARM processors for its Opteron series of processors. ARM servers represent an important shift in server-based computing. A traditional x86-class server with 12, 16, 24 or more cores increases performance by scaling up the speed and sophistication of each processor, using brute force speed and power to handle demanding computing workloads.
In comparison, an ARM server uses perhaps hundreds of smaller, less sophisticated, low-power processors that share processing tasks among that large number instead of just a few higher-capacity processors. This approach is sometimes referred to as “scaling out,” in contrast with the “scaling up” of x86-based servers.
The ARM architecture was originally developed by Acorn Computers in the 1980s.
PIPELINING
Introduction

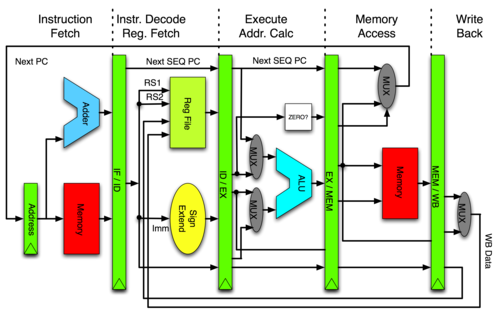
In computing, a pipeline, also known as a data pipeline,[1] is a set of data processing elements connected in series, where the output of one element is the input of the next one. The elements of a pipeline are often executed in parallel or in time-sliced fashion. Some amount of buffer storage is often inserted between elements.Pipelining is the process of accumulating instruction from the processor through a pipeline. It allows storing and executing instructions in an orderly process. It is also known as pipeline processing.
Pipelining is a technique where multiple instructions are overlapped during execution. Pipeline is divided into stages and these stages are connected with one another to form a pipe like structure. Instructions enter from one end and exit from another end.
Pipelining increases the overall instruction throughput.
In pipeline system, each segment consists of an input register followed by a combinational circuit. The register is used to hold data and combinational circuit performs operations on it. The output of combinational circuit is applied to the input register of the next segment.
Description
PIPELINING
Introduction
In computing, a pipeline, also known as a data pipeline,[1] is a set of data processing elements connected in series, where the output of one element is the input of the next one. The elements of a pipeline are often executed in parallel or in time-sliced fashion. Some amount of buffer storage is often inserted between elements.Pipelining is the process of accumulating instruction from the processor through a pipeline. It allows storing and executing instructions in an orderly process. It is also known as pipeline processing.
In computing, a pipeline, also known as a data pipeline,[1] is a set of data processing elements connected in series, where the output of one element is the input of the next one. The elements of a pipeline are often executed in parallel or in time-sliced fashion. Some amount of buffer storage is often inserted between elements.Pipelining is the process of accumulating instruction from the processor through a pipeline. It allows storing and executing instructions in an orderly process. It is also known as pipeline processing.
Pipelining is a technique where multiple instructions are overlapped during execution. Pipeline is divided into stages and these stages are connected with one another to form a pipe like structure. Instructions enter from one end and exit from another end.
Pipelining increases the overall instruction throughput.
In pipeline system, each segment consists of an input register followed by a combinational circuit. The register is used to hold data and combinational circuit performs operations on it. The output of combinational circuit is applied to the input register of the next segment.
Description
Arithmetic Pipeline
Arithmetic pipelines are usually found in most of the computers. They are used for floating point operations, multiplication of fixed point numbers etc. For example: The input to the Floating Point Adder pipeline is:
X = A*2^a
Y = B*2^b
Here A and B are mantissas (significant digit of floating point numbers), while a and b are exponents.
The floating point addition and subtraction is done in 4 parts:
- Compare the exponents.
- Align the mantissas.
- Add or subtract mantissas
- Produce the result.
Registers are used for storing the intermediate results between the above operations.
Arithmetic pipelines are usually found in most of the computers. They are used for floating point operations, multiplication of fixed point numbers etc. For example: The input to the Floating Point Adder pipeline is:
X = A*2^a
Y = B*2^b
Here A and B are mantissas (significant digit of floating point numbers), while a and b are exponents.
The floating point addition and subtraction is done in 4 parts:
- Compare the exponents.
- Align the mantissas.
- Add or subtract mantissas
- Produce the result.
Registers are used for storing the intermediate results between the above operations.
Instruction Pipeline
In this a stream of instructions can be executed by overlapping fetch, decode and execute phases of an instruction cycle. This type of technique is used to increase the throughput of the computer system.
An instruction pipeline reads instruction from the memory while previous instructions are being executed in other segments of the pipeline. Thus we can execute multiple instructions simultaneously. The pipeline will be more efficient if the instruction cycle is divided into segments of equal duration.
In this a stream of instructions can be executed by overlapping fetch, decode and execute phases of an instruction cycle. This type of technique is used to increase the throughput of the computer system.
An instruction pipeline reads instruction from the memory while previous instructions are being executed in other segments of the pipeline. Thus we can execute multiple instructions simultaneously. The pipeline will be more efficient if the instruction cycle is divided into segments of equal duration.
Balancing the stages
Since the throughput of a pipeline cannot be better than that of its slowest element, the designer should try to divide the work and resources among the stages so that they all take the same time to complete their tasks. In the car assembly example above, if the three tasks took 15 minutes each, instead of 20, 10, and 15 minutes, the latency would still be 45 minutes, but a new car would then be finished every 15 minutes, instead of 2.
Since the throughput of a pipeline cannot be better than that of its slowest element, the designer should try to divide the work and resources among the stages so that they all take the same time to complete their tasks. In the car assembly example above, if the three tasks took 15 minutes each, instead of 20, 10, and 15 minutes, the latency would still be 45 minutes, but a new car would then be finished every 15 minutes, instead of 2.
BUFFERING
Under ideal circumstances, if all processing elements are synchronized and take the same amount of time to process, then each item can be received by each element just as it is released by the previous one, in a single clock cycle. That way, the items will flow through the pipeline at a constant speed, like waves in a water channel. In such "wave pipelines"[2], no synchronization or buffering is needed between the stages, besides the storage needed for the data items.
More generally, buffering between the pipeline stages is necessary when the processing times are irregular, or when items may be created or destroyed along the pipeline. For example, in a graphics pipeline that processes triangles to be rendered on the screen, an element that checks the visibility of each triangle may discard it, if it is invisible, or may output two or more triangular pieces of it, if it is partly hidden. Buffering is also needed to accommodate irregularities in the rates at which the application feeds items to the first stage and consumes the output of the last one.
The buffer between two stages may be simply a hardware register with suitable synchronization and signalling logic between the two stages. When a stage A stores a data item in the register, it sends a "data available" signal to the next stage B. Once B has used that data, it responds with a "data received" signal to A. Stage A halts, waiting for this signal, before storing the next data item into the register. Stage B halts, waiting for the "data available" signal, if it is ready to process the next item but stage A has not provided it yet.
If the processing times of an element are variable, the whole pipeline may often have to stop, waiting for that element and all the previous ones to consume the items in their input buffers. The frequency of such pipeline stalls can be reduced by providing space for more than one item in the input buffer of that stage. Such a multiple-item buffer is usually implemented as a first-in, first-out queue. The upstream stage may still have to be halted when the queue gets full, but the frequency of those events will decrease as more buffer slots are provided. Queuing theory can tell the number of buffer slots needed, depending on the variability of the processing times and on the desired performance.
Under ideal circumstances, if all processing elements are synchronized and take the same amount of time to process, then each item can be received by each element just as it is released by the previous one, in a single clock cycle. That way, the items will flow through the pipeline at a constant speed, like waves in a water channel. In such "wave pipelines"[2], no synchronization or buffering is needed between the stages, besides the storage needed for the data items.
More generally, buffering between the pipeline stages is necessary when the processing times are irregular, or when items may be created or destroyed along the pipeline. For example, in a graphics pipeline that processes triangles to be rendered on the screen, an element that checks the visibility of each triangle may discard it, if it is invisible, or may output two or more triangular pieces of it, if it is partly hidden. Buffering is also needed to accommodate irregularities in the rates at which the application feeds items to the first stage and consumes the output of the last one.
The buffer between two stages may be simply a hardware register with suitable synchronization and signalling logic between the two stages. When a stage A stores a data item in the register, it sends a "data available" signal to the next stage B. Once B has used that data, it responds with a "data received" signal to A. Stage A halts, waiting for this signal, before storing the next data item into the register. Stage B halts, waiting for the "data available" signal, if it is ready to process the next item but stage A has not provided it yet.
If the processing times of an element are variable, the whole pipeline may often have to stop, waiting for that element and all the previous ones to consume the items in their input buffers. The frequency of such pipeline stalls can be reduced by providing space for more than one item in the input buffer of that stage. Such a multiple-item buffer is usually implemented as a first-in, first-out queue. The upstream stage may still have to be halted when the queue gets full, but the frequency of those events will decrease as more buffer slots are provided. Queuing theory can tell the number of buffer slots needed, depending on the variability of the processing times and on the desired performance.
Nonlinear pipelines
If some stage takes (or may take) much longer than the others, and cannot be sped up, the designer can provide two or more processing elements to carry out that task in parallel, with a single input buffer and a single output buffer. As each element finishes processing its current data item, it delivers it to the common output buffer, and takes the next data item from the common input buffer. This concept of "non-linear" or "dynamic" pipeline is exemplified by shops or banks that have two or more cashiers serving clients from a single waiting queue.
Source:Google
If some stage takes (or may take) much longer than the others, and cannot be sped up, the designer can provide two or more processing elements to carry out that task in parallel, with a single input buffer and a single output buffer. As each element finishes processing its current data item, it delivers it to the common output buffer, and takes the next data item from the common input buffer. This concept of "non-linear" or "dynamic" pipeline is exemplified by shops or banks that have two or more cashiers serving clients from a single waiting queue.
Source:Google